Summary
We created a parallel binary decision diagram (BDD) library using CilkPlus which allows us to find and count satisfying assignments to arbitrary boolean expressions efficiently. Our implementation achieves around 4x speedup on 16 cores and beats an existing BDD library by over 15x on large problems.
Background
BDD's are an efficient data structure for representing arbitrary boolean expressions. Using canonicity rules and duplicate detection, we can represent an exponentially growing data structure in manageable memory. The result is a directed acyclic graph that looks like the following graph generated by our library for 5-queens.

The user interactions with the library by declaring elementary BDD's and composing them together with standard boolean operations. The library is as simple as:
Bdd a(1);
Bdd b(2);
Bdd c = a & !b;
// Gives one satisfying assignment to the expression (returns <1:true, 2:false>)
unordered_map<Var, bool> map = c.one_sat();
// Count the number of satisfying assignments (returns 1 for a & !b)
int num = c.count_sat();The following mechanisms are required to generate the BDD:
- An efficient and multi-threaded hash table for storing BDD's so that each unique "subgraph" is only ever generated once.
- Another hash table for caching the results of intermediate operations for constructing the BDD and doing other operations.
- A set of logically consistent "rewrite" rules that allows us to enforce a canonical form on the structure of BDD's.
Most existing BDD libraries, including the well-know libraries BuDDy and CUDD, have efficient single-threaded implementations for the first two points and have a decent set of canonicity rules. However, according to the literature that we reviewed, there are huge opportunities for improvement on all three fronts:
- We can use a lock-free or fine-grained locking hash table to allow multi-threaded access to the uniques table and the cache.
- We can use fork-join parallelism to speed up the construction and count SAT operations since they are mostly recursive "divide-and-conquer"-like algorithms.
- We can decrease the number of unique elements by utilizing complement edges and it's associated rewrite rules.
Approach
We will first discuss the hash table we implemented. We initially wanted to implement a lock-free hash table to store unique BDD's as well as the cache. However, it turns out that the keys to our hash table would have be be at least 16 bytes long, which means we would have to use double-length compare-and-swap (CMPXCHG16B), which is unsupported by the Xeon Phi, which immediately killed that option.
Instead, we created a fine-grained open-addressing hash table. Our hash table takes an arbitrary length key and hashes it using the MurmurHash3 hashing scheme. After hashing the key to a bucket, we linearly probe for an open bin and acquire a lock on that bin before inserting the element. We initialize the hash table to a size that will ensure a low number of collisions.
Next, we will discuss the fork-join parallelism. One of the key operations for constructing a BDD is an "if-then-else" (ITE) expansion, which is used for composing any two BDD's together. ITE requires recursively traversing through the BDD graph, calling ITE independently twice per run. Since the two recursive calls are independent, they can be called in parallel. However, since we don't have enough cores to run all ITE calls in parallel together, we have to implement some sort of work queue in order to efficiently utilize all the cores as well as respect the execution order (the two recursive ITE calls have to finish before returning).
This model of computation is known as fork-join parallelism, which forks to spawn jobs that should be added to a work queue and joins to combine the results from forked jobs. Unfortunately, C++ semantics make it hard to implement arbitrary continuations (required for general fork-join) without compiler support. We choose to use CilkPlus, which provides parallel keywords for fork-join semantics.
Lastly, we will discuss the additional opportunities for canonicity rules. The BuDDy library represents BDD's without complemented edges. However, according to the literature, we can effectively represent a BDD and its complement with the same BDD by implementing a complex set of rewrite and canonicity rules. To do this with minimal memory footprint, we used a bit hack in order to encode the complement state in the existing pointer itself.
Results
To benchmark our library, we implemented a naive N-queens algorithm and compared runtimes with BuDDy and our library using varying amounts of cores on the Unix machines. Since the majority of the runtime is dominated by the BDD construction step, we specifically timed that step for the following graphs.
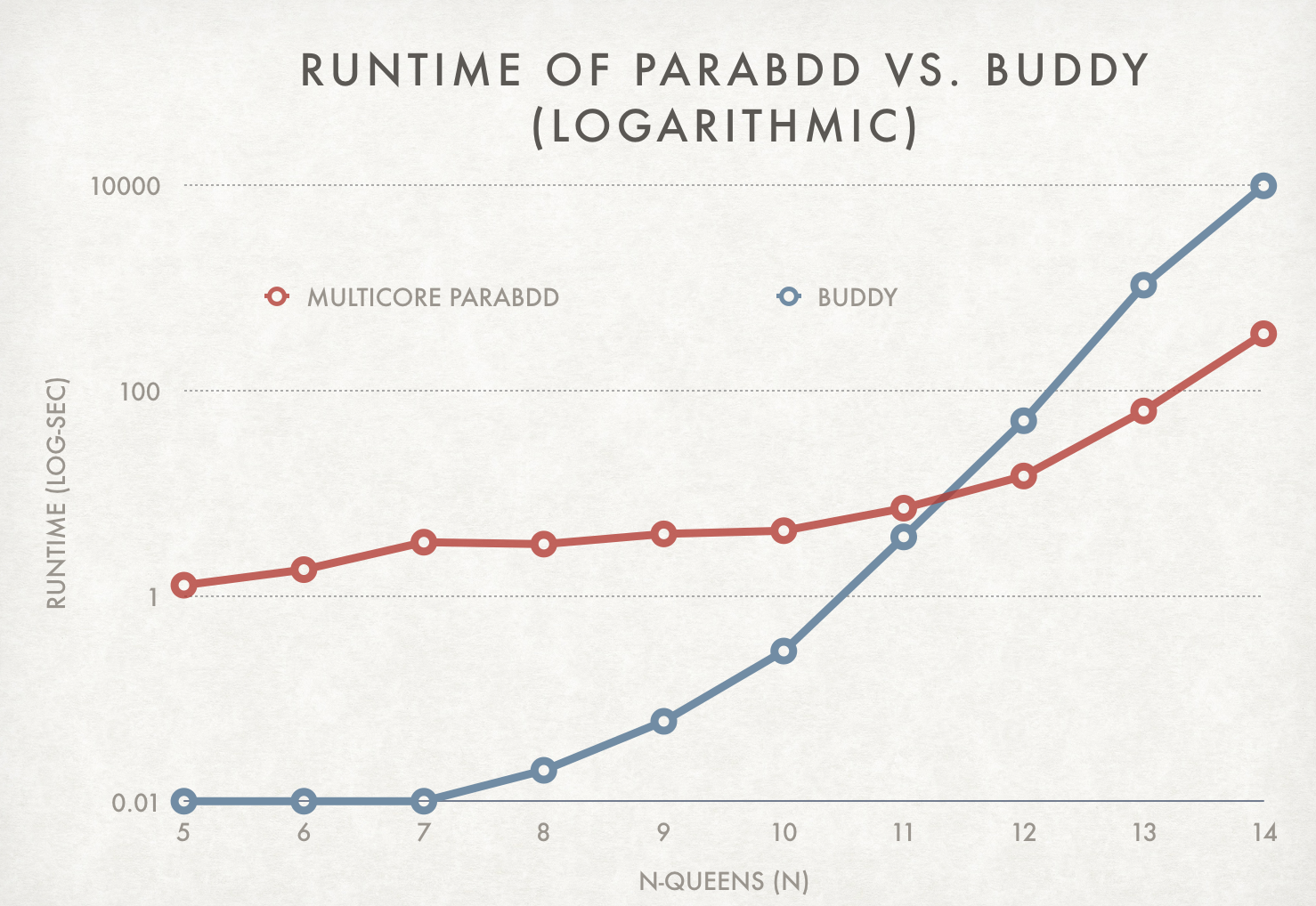

This graph shows our scaling as we increase the number of cores utilized. At the small n-queens, the runtimes are all the same because granularity control makes them all run sequentially. At 10-queens and larger, we achieve around 2x to 4x speedup over our sequential code. We achieve sub-linear speedup because construction of BDD's has high dependencies and a large amount of inherently sequential code.
Future Work
There are many additional optimizations that exist in current libraries that were not possible to implement in the scope of this project. Primarilty, the key optimizations are:
- Reordering rules to optimize the order that variables are constructed to minimize the BDD complexity
- Garbage collection for unused BDD's to reduce the peak memory footprint
In addition, in the process of designing the library, we encountered a major feature limitation of Cilk. Since there is a high amount of sharing, there is a small chance that work will be duplicated if one worker enters a job that another is already running. Ideally, what should happen is that the duplicated job should be descheduled and put at the end of the worker queue. Unfortunately Cilk does not provide this functionality. We hypothesize that this issue is a major limiting factor which prevents us from achieving near-linear speedup with higher numbers of cores.
References
- Van Dijk, Tom, Alfons Laarman, and Jaco Van De Pol. "Multi-core BDD operations for symbolic reachability." Electronic Notes in Theoretical Computer Science 296 (2013): 127-143.
- Somenzi, Fabio. "CUDD: CU Decision Diagram Package Release 3.0. 0." (2015).
- Bryant, Randal E. "Symbolic Boolean manipulation with ordered binary-decision diagrams." ACM Computing Surveys (CSUR) 24.3 (1992): 293-318.
List of Work
Equal work was performed by both project members.
The proposal and checkpoint status may be interesting.